Stima del Flusso di Materiale in Tempo Reale
Una rete neurale sviluppata su misura per hardware embedded, in grado di contare unità discrete con un errore inferiore al 5% alle portate di produzione.
Errore di conteggio alla portata ottimale
RMSE teorico dopo filtraggio temporale
Inferenza in locale - nessun cloud
Quando una macchina distribuisce migliaia di elementi al minuto, sapere quanti ne sono passati con esattezza è fondamentale per diversi aspetti, come la precisione di dosaggio, il controllo qualità e la tracciabilità di processo. La sfida principale è che alle velocità di produzione reali gli elementi si sovrappongono e si accumulano, rendendo inaffidabile qualsiasi conteggio diretto: occorre quindi un approccio più sofisticato.
Abbiamo sviluppato un sistema che analizza in continuo segnali raccolti da sensori e stima la portata in tempo reale, mantenendo un conteggio totale preciso senza mai interrompere il processo. Gira direttamente sull'hardware embedded della macchina - nessuna connessione cloud, quindi nessuna latenza - con errori inferiori all'1% nella fascia operativa principale.
La sfida
Per via di un accordo di riservatezza, non sono inclusi in questa pagina ulteriori dettagli sull'applicazione specifica o sul cliente.
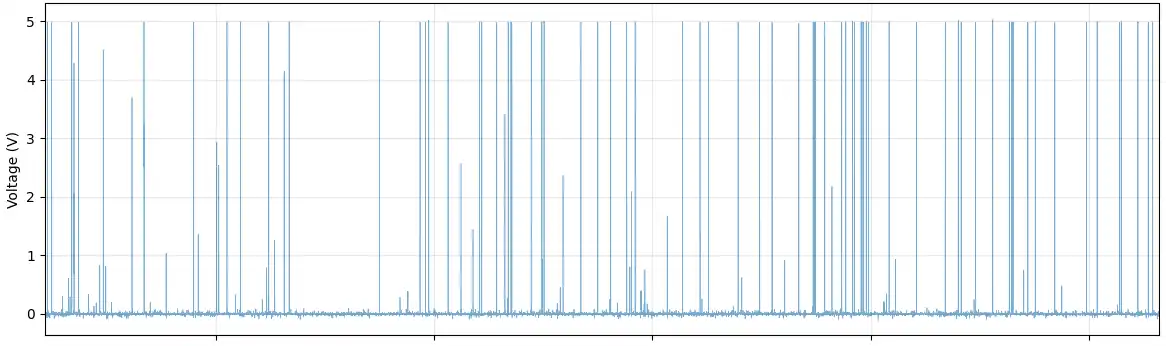
Il sistema hardware comprende più sensori analogici disposti lungo un canale di distribuzione. Al passaggio di ogni unità discreta, ciascun sensore produce un segnale continuo - ma ad alta portata le unità si sovrappongono e interferiscono tra loro, rendendo inaffidabile qualsiasi strategia di conteggio diretto basata sugli impulsi.
L'obiettivo è stimare la portata istantanea (unità al secondo) dai segnali multi-canale, integrarla nel tempo e ottenere così un conteggio totale. Il sistema deve operare in tempo reale su un dispositivo embedded, senza alcuna connessione cloud.
Perché la regressione standard non basta
L'analisi dei dati ha evidenziato una non-linearità critica: a bassa portata le unità passano una alla volta (regime discreto) e il segnale varia in modo prevedibile. Ad alta portata si sovrappongono e saturano i sensori (regime caotico). Questa transizione di fase fisica rende i modelli di regressione classici insufficienti.
La riduzione dimensionale ha confermato la struttura non lineare: la PCA cattura appena il 30% della varianza, mentre la t-SNE rivela due cluster ben distinti, uno per ciascun regime fisico. Si è reso quindi necessario ricorrere a un modello non lineare.
Il nostro approccio
Pipeline dati
I segnali grezzi multi-canale sono stati acquisiti a circa 20 kHz. Dopo il downsampling e la conversione in un formato binario compatto, il volume dei dati si è ridotto del 93% (da 40 GB a 2,9 GB) senza perdita di informazioni rilevanti. Una strategia a finestra scorrevole (finestre da 250 ms, hop da 50 ms, sovrapposizione dell'80%) consente di produrre stime della portata in tempo reale, adatte all'esecuzione su dispositivi edge.
Feature engineering
Abbiamo optato per estrarre feature da tre domini complementari:
Dominio Temporale
- Conteggio impulsi normalizzato e duty cycle
- Statistiche sulla durata degli impulsi e sull'intervallo inter-impulso
- Energia del segnale: RMS e area integrata totale
Dominio Frequenziale
- Centroide spettrale e larghezza di banda
- Potenza per bande di frequenza predefinite
- Coefficienti cepstrali in scala Mel (MFCC)
Cross-Canale
- Correlazione incrociata massima tra coppie di canali
- Lag alla correlazione massima e coerenza spettrale
- Co-occorrenze tra canali
L'analisi dell'importanza delle feature tramite permutazione ha confermato che le feature energetiche - Area Integrata Totale e RMS - sono le più predittive per la stima della portata in entrambi i regimi operativi.
Architettura del modello
Data la natura multi-regime del problema, è stata adottata una rete neurale artificiale (ANN) fully connected anziché un modello di regressione classica. Architettura e iperparametri sono stati ottimizzati con KerasTuner usando la strategia Hyperband - un metodo di ricerca efficiente che scarta precocemente le configurazioni meno promettenti. Il modello finale ha raggiunto una convergenza stabile, senza segni di overfitting.
Dalla portata al conteggio
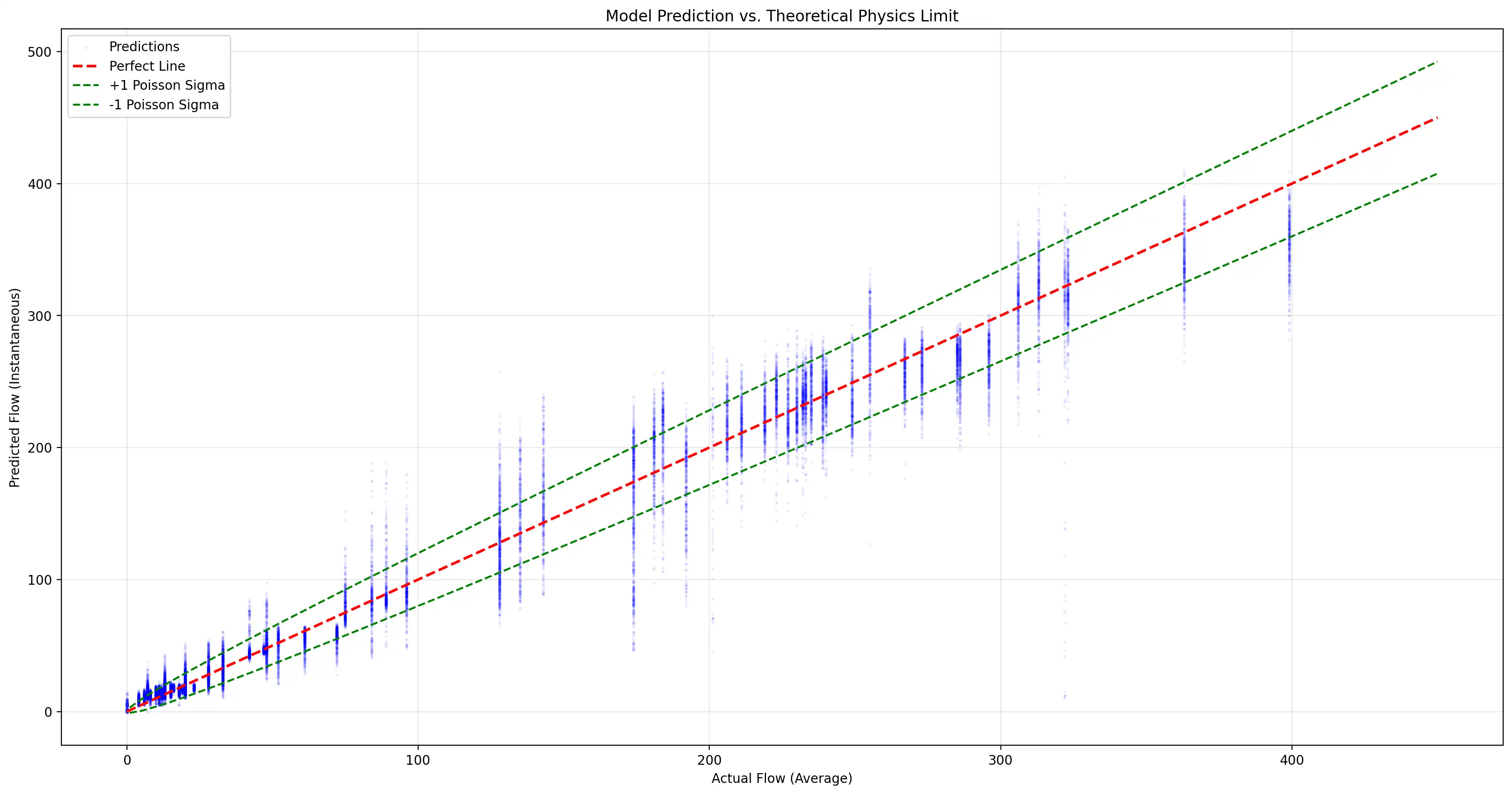
Le stime di portata istantanea vengono integrate tramite somma di Riemann, compensando opportunamente l'hop size per evitare doppi conteggi nelle finestre sovrapposte. Un filtro a media mobile da 2 secondi riduce il RMSE teorico da circa 20 unità/s (output grezzo della rete) a circa 3,2 unità/s - un miglioramento di 6 volte.
Risultati
Il modello è stato validato sull'intero range operativo della macchina:
| Portata | Errore di conteggio |
|---|---|
| Bassa (~80 u/s) | +10,2% |
| Media (~200 u/s) | +4,6% |
| Alta (~300 u/s) | −0,8% |
| Molto alta (~400 u/s) | −12,1% |
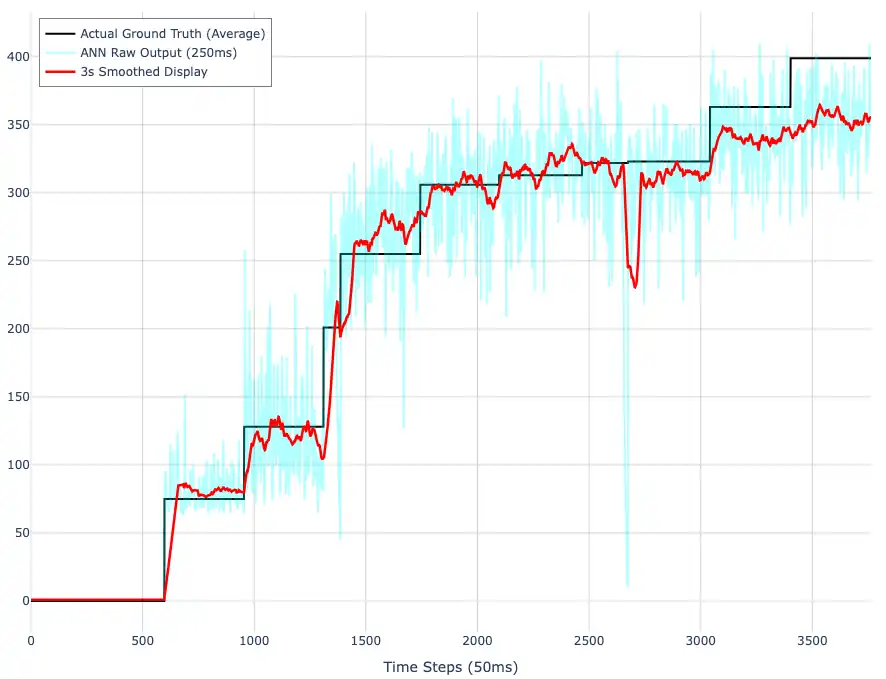
Il modello fornisce le prestazioni migliori nella fascia medio-alta (~200–350 u/s), che corrisponde al range operativo principale della macchina. Ad altissime portate, la saturazione del segnale produce una sottostima sistematica - un limite fisico intrinseco, non del modello.
Al punto operativo ottimale, il sistema raggiunge un errore inferiore all'1% - a fronte del circa 5% delle migliori soluzioni alternative disponibili sul mercato.
Il RMSE istantaneo di ~20 u/s è prossimo al limite di Poisson (~28 u/s) - la varianza irriducibile insita in qualsiasi processo di flusso discreto stocastico. Questo conferma che il modello sfrutta pressoché tutta l'informazione disponibile nel segnale.
Punti chiave
Inferenza Edge
Il modello viene eseguito interamente su hardware embedded, in tempo reale e senza necessità di cloud. Questo ne consente il funzionamento in condizioni operative di campo, eliminando qualsiasi latenza legata all'inferenza remota.
Design guidato dalla fisica
La comprensione della transizione di fase fisica tra i regimi di flusso ha orientato sia la scelta del modello sia la strategia di feature engineering - evitando l'errore di imporre un modello lineare a un sistema fondamentalmente non lineare.
Accuratezza ottimale
Il sistema opera in prossimità del limite di rumore di Poisson del processo fisico, a conferma che l'insieme delle feature e l'architettura del modello sono ben calibrati per il problema.
Metodologia generalizzabile
L'approccio - estrazione di feature multi-canale, regressione tramite ANN e integrazione temporale - è applicabile a qualsiasi problema di stima del flusso di unità discrete: granuli, pellet, componenti, compresse, in ambito industriale o agricolo.
Hai una sfida simile?
Siamo specializzati in Edge Machine Learning per applicazioni industriali complesse: contattaci per parlare insieme del tuo progetto!
Contattaci